no rebuttal
EDIT:
RAM
Let me put this bluntly - the memory configuration on the Series X is sub-optimal.
I understand
there are rumours that the SX had 24 GB or 20 GB at some point early in its design process but the credible leaks have always pointed to 16 GB which means that, if this was the case, it was very early on in the development of the console. So what are we (and developers) stuck with? 16 GB of GDDR6 @ 14 GHz connected to a 320-bit bus (that's 5 x 64-bit memory controllers).
Microsoft is touting the 10 GB @ 560 GB/s and 6 GB @ 336 GB/s asymmetric configuration as a bonus but it's sort-of
not. We've had this specific situation at least once before in the form of the
NVidia GTX 650 Ti and a similar situation
in the form of the 660 Ti. Both of those cards suffered from an asymmetrical configuration, affecting memory once the "symmetrical" portion of the interface was "full".
Interleaved memory configurations for the SX's asymmetric memory configuration including an averaged value and one where simultaneous access is possible using pseudo-channel mode. You can see that, overall, the Xbox SX will only ever reach the maximum access speeds if it's not ever accessing the less wide portion of the memory...
This diagram was updated to reflect the error I made below, by counting the 4x1 GB chips twice. Effective, averaged access drops to 280 GB/s when equal switching is performed across the two address spaces... I was over-estimating it before.
Now, you may be asking what I mean by "full". Well, it comes down to two things: first is that,
unlike some commentators might believe, the maximum bandwidth of the interface is limited to the 320-bit controllers and the matching 10 chips x 32 bit/pin x 14 GHz/Gbps interface of the GDDR6 memory.
That means that the maximum theoretical bandwidth is 560 GB/s,
not 896 GB/s (560 + 336). Secondly, memory has to be
interleaved in order to function on a given clock timing to improve the parallelism of the configuration. Interleaving is why you don't get a single 16 GB RAM chip, instead we get multiple 1 GB or 2 GB chips because it's vastly more efficient. HBM is a different story because the dies are parallel with multiple channels per pin and multiple frequencies are possible to be run across each chip in a stack, unlike DDR/GDDR which has to have all chips run at the same frequency.
However, what this means is that you need to have address space symmetry in order have interleaving of the RAM, i.e. you need to have all your chips presenting the same "capacity" of memory in order for it to work. Looking at the diagram above, you can see the SX's configuration, the first 1 GB of each RAM chip is interleaved across the entire 320-bit memory interface, giving rise to 10 GB operating with a bandwidth of 560 GB/s but what about the other 6 GB of RAM?
Those two banks of three chips either side of the processor house 2 GB per chip. How does that extra 1 GB get accessed? It can't be accessed at the same time as the first 1 GB because the memory interface is saturated. What happens, instead, is that the memory controller must instead "switch" to the interleaved addressable space covered by those 6x 1 GB portions. This means that, for the 6 GB "slower" memory (in reality, it's not slower but less wide) the memory interface must address that on a separate clock cycle if it wants to be accessed at the full width of the available bus.
The fallout of this can be quite complicated depending on how Microsoft have worked out their memory bus architecture. It could be a complete "switch" whereby on one clock cycle the memory interface uses the interleaved 10 GB portion and on the following clock cycle it accesses the 6 GB portion. This implementation would have the effect of averaging the effective bandwidth for all the memory. If you average this access, you get 280
392 GB/s for the 10 GB portion and 168 GB/s for the 6 GB portion for a given time frame but individual cycles would be counted at their full bandwidth.
I realised i was counting the 4x1 GB chips twice here - apologies for the mistake!
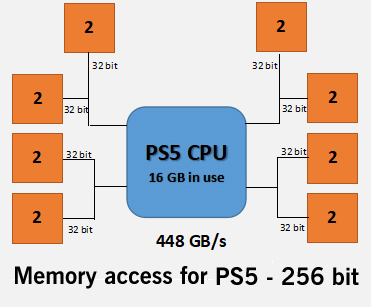
Interleaved memory configuration for the PS5's symmetric memory configuration... You can see that, overall, the PS5 has the edge in pure, consistent throughput...
However, there is another scenario with memory being assigned to each portion based on availability. In this configuration, the memory bandwidth (and access) is dependent on how much RAM is in use. Below 10 GB, the RAM will always operate at 560 GB/s. Above 10 GB utilisation, the memory interface must start switching or splitting the access to the memory portions. I don't know if it's technically possible to actually access two different interleaved portions of memory simultaneously by using the two 16-bit channels of the GDDR6 chip but if it were (and
the standard appears to allow for it), you'd end up with the
same 392/168 GB/s memory bandwidths
as the "averaged" shown in the diagram
scenario mentioned above.
If Microsoft were able to simultaneously access and decouple individual chips from the interleaved portions of memory through their memory controller then you could theoretically push the access to an asymmetric balance, being able to switch between a pure 560 GB/s for 10 GB RAM and a mixed 224 GB/s from 4 GB of that same portion and the full 336 GB/s of the 6 GB portion (also pictured above). This seems unlikely to my understanding of how things work and undesirable from a technical standpoint in terms of game memory access and also architecture design.
In comparison, the PS5 has a static 448 GB/s bandwidth for the entire 16 GB of GDDR6 (also operating at 14 GHz, across a 256-bit interface). Yes, the SX has 2.5 GB reserved for system functions and we don't know how much the PS5 reserves for that similar functionality but it doesn't matter - the Xbox SX either has only 7.5 GB of interleaved memory operating at 560 GB/s for game utilisation before it has to start "lowering" the effective bandwidth of the memory
below that of the PS5...
or the SX has an averaged mixed memory bandwidth that is
always below that of the baseline PS4. Either option puts the SX at a disadvantage to the PS5 for more memory intensive games and the latter puts it at a disadvantage all of the time.
| The Xbox's custom SSD hasn't been entirely clarified yet but the majority of devices on the market for PCIe 4.0 operate on an 8 channel interface... |
Moving onto the I/O and SSD access, we're faced with a similar scenario - though Microsoft have done nothing sub-optimal here, they just have a slower interface.
14 GHz GDDR6 RAM operates at around 1.75 GB/s per pin, per chip (14 Gbps [32 data pins per chip x 10 chips gives total potential bandwidth of 560 GB/s - matching the 320-bit interface]). Originally, I was concerned that would be too close to the total bandwidth of the SSD but Microsoft have upgraded to a 2.4/4.8 GB/s read interface with their SSD which is, in theory, enough to utilise the equivalent of 1.7% of 5 GDDR6 chips uploading the decompressed data in parallel each second, leaving a lot of overhead for further operations on those chips and the remaining 6 chips free for completely separate operations. (4.8 GB/5 (1 GB) chips /1.75x32 GB/s)
In comparison, SONY can utilise the equivalent of 3.2% of the bandwidth of 6 GDDR6 chips, in parallel, per second (9 GB/5 (2 GB) chips /(1.75x32 GB/s)) due to the combination of a unified interleaved address space and unified larger RAM capacity (i.e. all the chips are 2 GB in capacity so, unlike the SX, the interface does not need to use more chips [or portion of their total bandwidth] to store the same amount of data).
Turning this around to the unified pool of memory, the SX can utilise 0.86% of the total pin bandwidth whereas the PS5 can use 2.01% of the total pin bandwidth, all of this puts the SX at just under half the theoretical performance (ratio of 0.42) of the PS5 for moving things from the system storage.
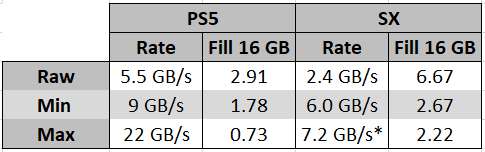
Unfortunately, we don't know the random read IOPS for either console as this number will more accurately reflect the real world performance of the drives but going on the above figures this means is that the SX can fill the RAM with raw data (2.4 GB/s) in 6.67 seconds whereas the PS5 can fill the RAM (5.5 GB/s) in 2.9 seconds, again, 2.3x the rate of the SX (this is just literally the inverse ratio of the above comparison with the decompressed data).
However, that's not the entire story. We also have to look at the custom I/O solutions and other technology that both console makers have placed on-die in order to overcome many potential bottlenecks and limitations:
The decompression capabilities and I/O management of both consoles are very impressive, but again, SONY edges out Microsoft with the equivalent of
10-11 Zen 2 CPU cores to
5 cores in pure decompression power. This optimisation on SONY's part really lifts all of the pressure off of the CPU, allowing it to be almost entirely focussed on the game programme and OS functions. That means that the PS5 can move up to 5.5 GB/s compressed data from the SSD and the decompression chip can decompress up to 22 GB/s from that 5.5 GB compressed data, depending on the compressibility of that underlying raw data (with 9 GB as a lower bound figure).
| Data fill rates for the entire memory configuration of each console; the PS5 unsurprisingly outperforms the SX... *I used the "bonus" 20% figure for the SX's BCPack compression algorithm. |
Meanwhile, the SX can move up to 4.8 GB/s of compressed data from the SSD and the decompression chip can decompress up to 6 GB/s of compressed data. However, Microsoft also have a specific decompression algorithm for texture data* called
BCPack (an evolution of
BCn formats) which can potentially add another 20% compression on top of that achieved by the PS5's Kraken algorithm (which this engineer estimates at a 20-30% compression factor). However, that's not an apples-to-apples comparison because this in on uncompressed data, whereas the PS5 should be using a form of
RDO which the same specialist reckons will bridge the gap in compression of texture data when combined with Kraken. So, in the name of fairness and lack of information, I'm going to leave only the confirmed stats from the hardware manufacturers and not speculate about further potential compression advantages.
*Along with prediction engines that try to reduce the amount of texture data moved to memory called Sampler Feedback Streaming [SFS] which improve efficiency of RAM usage - in terms of texture use - by 2x-3x. i.e. 2.7 MB per 4K texture instead of 8 MB.
While the SFS won't help with data loading from the SSD, it will help with data management within the RAM, potentially allowing for less frequent re-loading of data into RAM - which will improve the efficiency of the system, overall - something which is impossible to even measure at this point in time - especially because the PS5 will also have systems in place to manage data more intelligently.**
[UPDATE] After reading an explanation from James Stanard (over on Twitter) regarding how SFS works, it seems that it does also help reduce loading of data from the SSD. I had initially thought that this part of the velocity architecture was silicon-based and so the whole MIP would need to be loaded into a buffer from the SSD before the unnecessary information was discarded prior to loading to RAM but apparently it's more software-based. Of course, the overall, absolute benefit of this is not clear - not all data loaded into the RAM is texture data and not all of that is the highest MIP level. PS5 also has similar functionality baked into the coherency engines in the I/O but that has not been fully revealed as-yet so we'll have to see how this aspect of the two consoles stacks up. Either way, reducing memory overhead is a big part of graphics technology for both NVidia and AMD so I don't think this is such a big deal...